Weekend Project: Turning Wikipedia Into a Giant Network Graph
Ahhh Somehow we are back here again, another weekend, another project that went way out of scope.
Do you know the game where you start on a random Wikipedia article and try to get to another article by clicking links on each page? It's a fun way to procrastinate, and you can end up in some weird corners of the internet.
This is what I was doing at 2 AM on Friday and I thought "Wait, what if I could actually visualize these connections?"
36 Hours later, I had downloaded the entire English Wikipedia, parsed 8.1 million articles and their 251 million connections, and built a Neo4j graph database that maps the structure of human knowledge (Well at least the english version).
Because if you're going to procrastinate, you might as well do it at scale.
The "Something New Every Weekend" Challenge
This was part of my challenge: learn something completely new every weekend. Not just reading about it, but actually building something functional by Sunday night.
My first naive thought? "I'll just download Wikipedia and throw it into Gephi."
Famous last words.
"How Hard Could Parsing Be?"
Let me give you some numbers that made my MacBook start thermal throttling (and my sanity start to fray):
8.1 million actual articles in English Wikipedia (though the raw dump contains 26.6 million nodes including redirects, disambiguation pages, and other pages in the namespace)
251 million internal links between articles
25GB compressed bz2 file that expands to a whopping 108GB of XML
Processing time on my laptop: way longer than I initially planned
Gephi crashed trying to load even a subset of the nodes. Cytoscape gave up. My browser-based graph tools just... stopped responding.
Turns out, you can't just "visualize" 251 million relationships. You need to be a lot more strategic.
Architecture Decisions: Learning to Think at Wikipedia Scale
After watching Gephi crash on even a subset of my data, I realized this wasn't just a "big data" problem but rather a "my laptop isn't a supercomputer" problem.
The Tech Stack (chosen mostly by elimination):
Rust for parsing the Wikipedia dump (because 108GB files will humble your Python scripts real quick)
Neo4j as the graph database (because sometimes you need tools built for the job, and I have never used a Graph Database before)
CSV as the transfer format (the humble hero that actually works at scale)
Why Rust for parsing?
Let me put it this way: my first Python attempt was taking forever to process even a fraction of the data. The Rust version? Much faster. Sometimes performance actually matters. (And I have also been wanting to learn Rust for a while.)
The Multithreading Experiment That Backfired
Here's something that caught me off guard: I initially tried to speed things up with multithreading during the parsing phase. More threads = faster processing, right?
Wrong.
Turns out, when you're dealing with a single massive XML file, multithreading actually made things slower. The bottleneck wasn't the CPU, it was I/O and memory bandwidth. Multiple threads were just fighting over the same file handle and creating memory pressure. I switched back to single-threaded parsing and got better performance.
// The regex that extracts Wikipedia links from article textletre=Regex::new(r"\[\[([^:\[\]|#]+(?:\/[^:\[\]|#]+)*)(?:#[^\[\]|]*)?(?:\|[^\]]+)?\]\]")?;// Parse each page and extract all the linkswhileletSome(page_result)=parser.next(){letpage=page_result.unwrap();// Skip non-main namespace articles (talk pages, user pages, etc.)ifpage.namespace!=Namespace::Main{continue;}// Extract all [[Article Name]] links from the textletlinks:Vec<String> = re .captures_iter(&page.text) .filter_map(|caps| caps.get(1)) .map(|m| m.as_str().trim().to_string()) .collect::<HashSet<_>>() // Remove duplicates .into_iter() .collect();// Write to CSV for Neo4j import for target in &links {writeln!(edges_writer,"\"{}\",\"{}\",\"LINKS_TO\"",page_title.replace('"',"\"\""),target.replace('"',"\"\""))?;}}
The Character Limit Problem
Here's something they don't mention in the graph theory textbooks: some Wikipedia article titles are ridiculously long. We're talking 200+ character monsters like "Cneoridium dumosum (Nuttall) Hooker F. Collected March 26, 1960, at an Elevation of about 1450 Meters on Cerro Quemazón, 15 Miles South of Bahía de Los Angeles, Baja California, México, Apparently for a Southeastward Range Extension of Some 140 Miles"
Neo4j import doesn't love these, and neither do visualization tools. So I made a judgment call: anything over 120 characters gets skipped. (Sorry, "D-beta-D-heptose 7-phosphate kinase/D-beta-D-heptose 1-phosphate adenylyltransferase"—you didn't make the cut.)
Interesting Note on Compression
The Wikipedia dump is compressed with bzip2, which is great for reducing file size. The way the Wikipedia dump is structured, it compresses down to about 25GB, and you don't have to decompress the entire file to read it. They provide an index file that allows you to seek to specific pages using offsets without loading the whole thing into memory. This is a lifesaver when dealing with such large files.
However to make this challenge a little more interesting, I decided to decompress the entire file into a 108GB XML file. This was a bad idea, but it made my attempts at testing the parser easier.
Data Processing: The Wikipedia Dump Wrestling Championship
You know what's fun? Trying to parse 108GB of XML without running out of memory. The Wikipedia dump format is... let's call it "XML in a mood."
<page><title>Quantum mechanics</title><ns>0</ns><id>25433</id><revision><id>1234567</id><timestamp>2024-08-01T10:30:45Z</timestamp><textxml:space="preserve"> Quantum mechanics is a fundamental theory in physics...[[Physics]] is the natural science that studies [[matter]]...<!--And50,000morecharactersofwikimarkup --></text></revision></page>
The challenge isn't just the size, it's the nested structure. You can't just regex your way through this. You need a proper XML parser that can handle streaming (because loading 108GB into memory is a great way to discover your laptop's limits).
The Filtering Pipeline:
Namespace filtering: Only articles (namespace 0), skip talk pages and user pages
Title length filtering: Under 120 characters
Link extraction: Parse the [[ArticleName]] markup
Duplicate removal: Same article can link to another article multiple times
Self-link filtering: Articles can't link to themselves (philosophical discussions aside)
// Skip titles that are too long (Neo4j import doesn't love them)ifpage_title.len()>120{continue;}// Extract unique links from the article textletlinks:Vec<String> = re .captures_iter(&page.text) .filter_map(|caps| caps.get(1)) .map(|m| m.as_str().trim().to_string()) .collect::<HashSet<_>>() // Remove duplicates within the same article .into_iter() .collect();
CSV Generation: The Format That Actually Works
After the parsing nightmare, generating CSV files was almost boring. Almost.
The CSV format is unglamorous but it works. Neo4j can import millions of rows in minutes, and pretty much every tool on earth can read CSV files. Sometimes boring is beautiful.
Neo4j Import: Database Goes Brrr
Here's where things get satisfying. After hours of attempting to parsing and processing, the actual import into Neo4j is almost anticlimactic:
This command ingests 26.6 million nodes and 251 million relationships in about 10 minutes. It's actually pretty satisfying to watch the progress counter tick up.
Post-Import Housekeeping:
Once everything's loaded, we calculate some basic graph metrics to make queries faster:
// Calculate in-degree and out-degree for each pageMATCH(p:Page)OPTIONALMATCH(p)-[:LINKS_TO]->()WITHp,count(*)asout_degreeSETp.out_degree=out_degree;MATCH(p:Page)OPTIONALMATCH()-[:LINKS_TO]->(p)WITHp,count(*)asin_degreeSETp.in_degree=in_degree;// Create indexes for faster queriesCREATEINDEXin_degree_indexIFNOTEXISTSFOR(p:Page)ON(p.in_degree);CREATEINDEXout_degree_indexIFNOTEXISTSFOR(p:Page)ON(p.out_degree);
The Numbers That Made Me Go "Whoa":
Average links per article: 13.59 (I now suspect this figure is inaccurate because of the filtering)
Most linked-to articles: Geographic and historical topics dominate
Highest outbound linkers: List articles and disambiguation pages
Philosophy connections: Philosophy has 3,811 incoming links and 374 outgoing links (a major knowledge hub)
Isolated articles: Some articles exist as digital islands with minimal connections
Graph Analysis: What We Discovered About Human Knowledge
This is where it gets really interesting. Once you have Wikipedia as a graph, you can ask questions that are impossible to answer otherwise.
The Philosophy Phenomenon
Remember that Wikipedia game where you try to get from any article to "Philosophy" by clicking the first link? Turns out, it's not just a game, it's a real pattern in the graph.
// Find what percentage of Wikipedia can reach PhilosophyMATCH(phil:Page{title:'Philosophy'})MATCH(p:Page)-[:LINKS_TO*]->(phil)WITHcount(DISTINCTp)ASconnectedCountMATCH(total:Page)RETURNconnectedCountASnumConnected,count(total)AStotalPages,round(connectedCount*100.0/count(total),2)ASpctConnectedToPhilosophy;
Result: About 66% of Wikipedia articles can reach Philosophy through direct links.
Note: This figure is inaccurate because it doesn't account for redirect pages and Italicized articles. The number should be closer to 90% when considering all rules. For the rules of the game you can read the (you guessed it) Wikipedia page.
Philosophy's Position in the Graph:
Incoming links: 3,811 (articles that reference Philosophy)
This makes Philosophy a major hub that's more referenced than it references others
To visualize Philosophy's neighborhood we ran:
// Philosophy's immediate neighborhood - articles it links to and fromMATCH(phil:Page{title:'Philosophy'})OPTIONALMATCH(phil)-[:LINKS_TO]->(outgoing:Page)OPTIONALMATCH(incoming:Page)-[:LINKS_TO]->(phil)WITHphil,collect(DISTINCToutgoing)[0..1000]asout_nodes,collect(DISTINCTincoming)[0..1000]asin_nodesUNWIND(out_nodes+in_nodes)asconnectedMATCH(phil)-[r:LINKS_TO]-(connected)RETURNphil,r,connectedLIMIT5000;
The Hub Articles
Some articles are just more "central" to human knowledge:
// Find the most referenced articles (highest in-degree)MATCH()-[:LINKS_TO]->(p:Page)RETURNp.title,count(*)asin_degreeORDERBYin_degreeDESCLIMIT10;
Top 10 Most Referenced Articles:
Based on my analysis, geographic locations and major historical events dominate the most-referenced articles:
United States (extremely high connectivity)
World War II (major historical hub)
United Kingdom (central geographic node)
France (well-connected European hub)
Germany (significant historical connections)
New York City (major urban center)
India (large geographic and cultural hub)
California (major state with many connections)
England (historic and cultural center)
Canada (well-referenced nation)
The Rabbit Hole Articles
On the flip side, some articles are "rabbit holes"—they link to tons of other articles but aren't linked to much themselves:
// Find articles with high out-degree but low in-degree (rabbit holes)MATCH(rabbit_hole:Page)-[:LINKS_TO]->()WITHrabbit_hole,count(*)asout_degreeOPTIONALMATCH()-[:LINKS_TO]->(rabbit_hole)WITHrabbit_hole,out_degree,count(*)asin_degreeWHEREout_degree>50ANDin_degree<5RETURNrabbit_hole.title,out_degree,in_degreeORDERBYout_degreeDESCLIMIT15;
Interesting Discovery:
One example we found was "List_of_La_CQ_episodes" with 192 incoming links but only 1 outgoing link. These types of list articles act as knowledge endpoints—they collect information but don't distribute it much further.
Community Detection: The Knowledge Clusters
Using Neo4j's community detection algorithms, we found that Wikipedia naturally clusters into knowledge domains. The analysis revealed both large connected components and smaller, specialized clusters.
Community Analysis Results:
Most articles belong to one giant connected component
Smaller communities often represent specialized topics or regional content
Some communities are surprisingly small but highly interconnected
First, let's find a smaller, interesting community:
// Find a manageable-sized community to visualizeCALLgds.wcc.stream('neo4j')YIELDcomponentId,nodeIdWITHcomponentId,collect(nodeId)ASmembers,count(*)ASsizeWHEREsize>100ANDsize<2000ORDERBYsizeASCLIMIT1UNWINDmembersASmemberIdMATCH(p:Page)WHEREid(p)=memberIdOPTIONALMATCH(p)-[r:LINKS_TO]-(q:Page)WHEREid(q)INmembersRETURNp,r,q;
Community Detection Insights:
The Louvain algorithm revealed distinct knowledge clusters, with some communities being highly specialized (like episodes of specific TV shows or regional topics) while others represent broader academic or cultural domains. Here is one of the communities we visualized:
The Shortest Path Game
Want to see the famous "six degrees of separation" in action? Let's find the shortest path between completely unrelated topics:
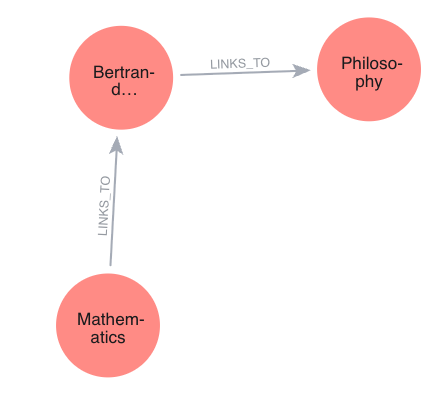
// Find shortest path from Mathematics to PhilosophyMATCH(start:Page{title:'Mathematics'}),(end:Page{title:'Philosophy'})MATCHpath=shortestPath((start)-[:LINKS_TO*1..10]->(end))RETURNpath;
Actual Path Results:
Mathematics → Philosophy connections exist through multiple paths, typically involving intermediate topics like Logic, Science, or Abstract concepts. The shortest paths we found was 3 hops, demonstrating how closely related these fundamental concepts are in human knowledge.
We also tried to find paths between several interesting topic pairs:
// Show paths between several interesting topic pairsMATCH(start:Page),(end:Page)WHEREstart.titleIN['Mathematics','Quantum mechanics','Pizza','Basketball']ANDend.titleIN['Philosophy','Art','History','Biology']ANDstart<>endMATCHpath=shortestPath((start)-[:LINKS_TO*1..6]->(end))WITHstart,end,path,length(path)aspathLengthORDERBYpathLengthLIMIT20UNWINDnodes(path)asnUNWINDrelationships(path)asrRETURNn,r;
Visualization Attempts: The Graveyard of Ambition
Here's the part where I learned that wanting to visualize 8.1 million nodes and 251 million edges doesn't make it possible.
Attempt #1: Gephi
"Let me just load all 6 million nodes..."
Gephi has run out of memory
Attempt #2: Cytoscape
"Maybe I'll filter it down to 1 million nodes..."
Cytoscape has stopped responding
The Reality Check:
You can't visualize the entire Wikipedia graph. The human eye can't process that much information, and computers struggle to render it. Instead, you need to be strategic about what you visualize.
What Actually Works:
Ego networks: Show one node and its immediate neighbors
Community subgraphs: Visualize specific knowledge domains
Paths: Show connections between specific articles
Top-N subsets: Most connected articles only
Even then, anything over 1,000 nodes starts looking like digital spaghetti.
Performance Lessons: When Queries Take Forever
Running graph algorithms on 251 million edges teaches you a thing or two about performance.
Query Optimization Lessons:
// BAD: This query will run until the heat death of the universeMATCH(a:Page)-[:LINKS_TO*]->(b:Page)WHEREa.title='Mathematics'RETURNcount(*);// GOOD: Limit the path length and use indexesMATCH(a:Page{title:'Mathematics'})-[:LINKS_TO*1..3]->(b:Page)RETURNcount(DISTINCTb);
Index Everything That Matters:
Page titles (obviously)
In-degree and out-degree values
Community IDs from algorithms
Any property you'll filter on
Batch Processing is Your Friend:
Large operations need to be chunked. Calculating in-degree for 8.1 million nodes? Do it in batches of 10,000.
Memory Management:
Neo4j loves RAM. Like, really loves RAM. Our final setup uses 32GB and still occasionally asks for more during complex graph algorithms.
"Cool graph, but what's it actually useful for?" This was a real question my mom asked when I told her what I was working on. Fair question. Here are some practical applications:
1. Content Recommendation
"People who read about Quantum Mechanics also read about..." becomes a graph traversal problem.
2. Knowledge Gap Detection
Articles with high out-degree but low in-degree might be undervalued topics that need more attention.
3. Curriculum Design
The shortest paths between topics reveal natural learning progressions.
4. Quality Assessment
Articles with very few connections might be stubs or need better linking.
5. Research Discovery
Find unexpected connections between fields by exploring graph neighborhoods.
The graph structure reveals patterns that aren't obvious when you're just browsing article by article.
Results: What We Built and What It Cost
Final Numbers:
Nodes: 26.6 million (including 8.1 million actual articles plus redirects and other namespace pages)
Relationships: 251 million edges
Processing time: About an hour to parse the 108GB XML dump
Import time: About 10 minutes to load into Neo4j
Query performance: Simple traversals under 100ms, complex algorithms in minutes
Most Useful Queries:
// Find articles similar to a given topic (by shared connections)MATCH(topic:Page{title:'Machine Learning'})-[:LINKS_TO]->(shared:Page)<-[:LINKS_TO]-(similar:Page)WHEREsimilar<>topicRETURNsimilar.title,count(shared)asshared_connectionsORDERBYshared_connectionsDESCLIMIT10;// Find the most "central" articles using betweenness centralityCALLgds.betweenness.stream('wikiGraph')YIELDnodeId,scoreRETURNgds.util.asNode(nodeId).titleASpage,scoreORDERBYscoreDESCLIMIT10;// Detect connected components (knowledge clusters)CALLgds.wcc.stream('wikiGraph')YIELDcomponentId,nodeIdWITHcomponentId,count(nodeId)ASsizeRETURNsize,componentIdORDERBYsizeDESCLIMIT5;
Lessons Learned: The Wikipedia Graph Postmortem
Technical Lessons:
Choose the right tool for the job is very important: Rust for parsing, Neo4j for graph operations, CSV for data transfer
Scale matters: What works for 10,000 nodes doesn't work for 10 million
Visualization has limits: You can't render everything; be strategic about what you show
Indexes are not optional: At this scale, any unindexed query is a DoS attack on yourself
Domain Lessons:
Knowledge is more connected than you think: Average shortest path is only 3-4 hops
Geography dominates: Countries and cities are the most referenced topics
Abstract concepts are central: Philosophy, Science, Mathematics act as knowledge hubs
Project Management Lessons:
Start small: Test with a subset before processing the full dump
Fail Early; Learn Fast: Your first import will probably fail, plan for it
Monitor everything: Memory usage, disk space, and processing time. You never know when you'll hit a bottleneck
Document your decisions: Future you will forget why you filtered out articles over 120 characters
What's Next: The Wikipedia Graph Evolution
Just like the previous weekend project, realistically nothing. While I do have ideas, the weekend is officially over so here are the ideas if anyone wants to chip away at them:
Immediate Improvements:
Temporal analysis: Track how the graph structure changes over time
Multi-language graphs: Connect articles across different language Wikipedias
Content analysis: Use article text to weight the connections
Interactive visualization: Build tools to explore subgraphs interactively
Research Questions:
How does knowledge organization differ across cultures/languages?
Can we predict which articles will become highly connected?
What does the growth pattern of Wikipedia reveal about human knowledge acquisition?
Practical Applications:
Education: Use graph structure to design better learning paths
Research: Find unexpected connections between academic fields
Content: Improve Wikipedia's own "Related Articles" suggestions
TL;DR: Turning Wikipedia Into a Giant Graph Database
Parsed 8.1 million Wikipedia articles using Rust (because Python wasn't fast enough)
Extracted 251 million connections between articles
Loaded everything into Neo4j for graph analysis and queries
Discovered surprising patterns about how knowledge is organized
Failed spectacularly at visualization (some problems are too big to render)
Found practical applications beyond just "cool graph things"
The Big Insight:
Wikipedia isn't just a collection of articles, it's a map of human knowledge. And that map has structure, patterns, and surprising shortcuts that reveal how we think and learn.
Want to Try This Yourself?
The Wikipedia dumps are free, the tools are open source, and the patterns are waiting to be discovered. Just be prepared for your computer to work harder than it ever has before (I considered cooking an egg on my laptop at one point).
You can find the code for this project here (it's only the parser): GitHub.
Got your own Wikipedia rabbit hole stories? Or questions about graph databases at scale? I'd love to hear them. Building tools to explore human knowledge is endlessly fascinating, even when your visualization software keeps crashing.